The Plastiq Papers
Big-picture perspectives and fresh takes from Plastiq.
It’s been a busy and difficult few days for the entire banking industry. As many are.. read
December 07, 2022 02:10 PM EST Rayna Kumar: Good morning, afternoon, everyone. I’m Rayna Kumar, and.. read
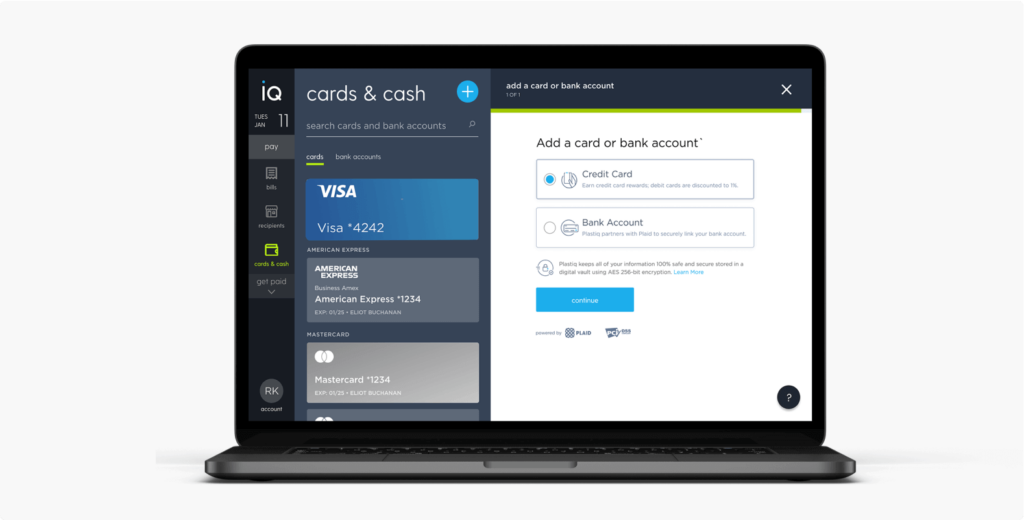
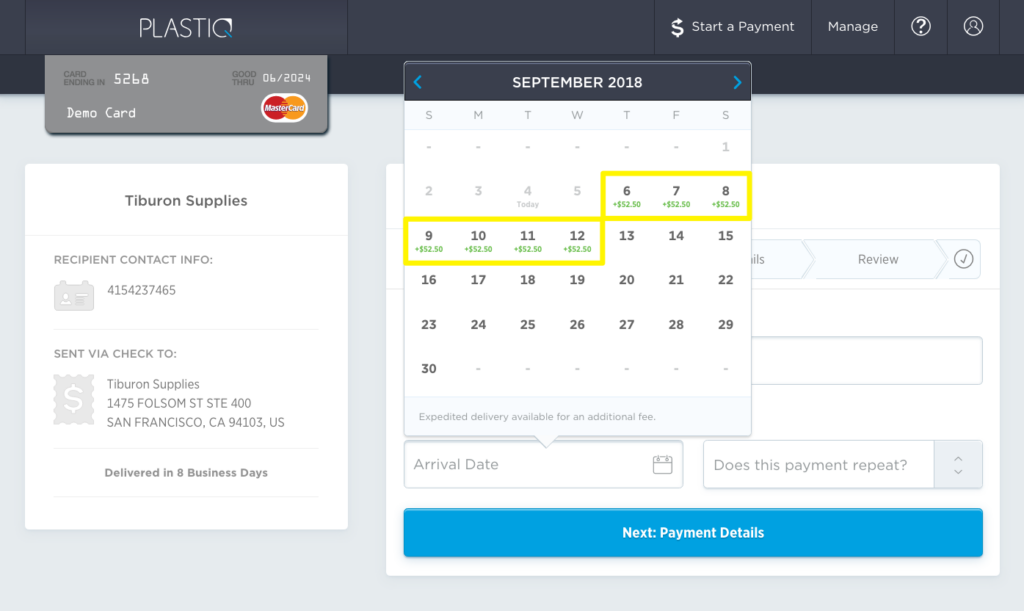
Ready to pay your suppliers through Plastiq? Here’s a short guide with a tour of our.. read
If you’re looking for ways to grow your business, you might’ve come across the idea of.. read
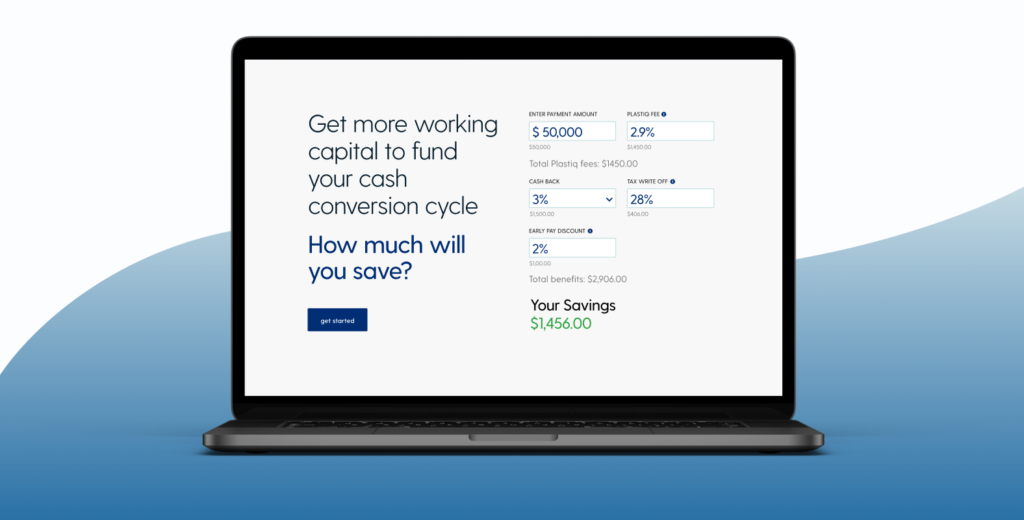
Growing your business requires investment. Easier access to working capital can help you scale faster. Credit.. read

In this white paper, Plastiq’s VP of Product, Aditya Mishra does a deep dive into the.. read
There is at least one, undebatable truth when it comes to a business. Regardless of size.. read

If you own and operate a business today, you’re probably knee deep in the many, many.. read

We’re excited to bring you our latest playbook on how businesses can improve cash flow and.. read

Popular customer segments served by Plastiq are DTC brands, retailers, and wholesalers. These businesses leverage Plastiq.. read

As the pandemic economy, impacted supply chains, and record inflation converge on the manufacturing sector, cash.. read

By: Tal Yeshanov – Director, Risk and Strategic Financial Operations By: Tal Yeshanov – Director, Risk.. read

On his podcast The Small Business Edge, entrepreneur Brian Moran sat down with James Barood, a.. read

Managing cash flow plays a pivotal role in every business’s ability to, frankly put, survive in.. read

Stoyan Kenderov, Plastiq’s Chief Operating Officer, joined a recent PYMNTS panel to talk about how SMBs.. read

Small business entrepreneur, Brian Moran, brought author, speaker and e-commerce expert John Lawson on The Small.. read

On-the-go bill pay evolved. Plastiq is excited to announce our newest evolution in accounts payable processing:.. read

In 2020, small businesses scrambled to adapt to lockdowns and new remote work protocols. Businesses where.. read

No matter what industry you’re in, you’re in the business of making money. But too often,.. read

In its 2021 State of Small Business Cash Flow, Intuit Quickbooks reported that 60% of small.. read
If you run a small business, it’s probably no surprise that 93% of businesses are paid.. read

During the pandemic, the demand for safe, no-touch, in-person payment methods has skyrocketed, and the popularity.. read

A recent McKinsey report showed that businesses waste 2% of their hard earned profits on just.. read

Going into 2020, the 2019 American Express State of Women-Owned Businesses Report found the number of.. read

When Guidant Financial and the Small Business Trend Alliance surveyed businesses at the end of last.. read

It’s no mystery that taking time off can be good for your mental health, but it.. read

Lillian Liang started her time at Plastiq as a contract software engineer, but the fit was.. read

Meet Plastiq’s own Eric Normant, VP, Engineering. A little over a year ago, Eric joined Plastiq,.. read

The economy will recover from the pandemic. There’s no doubt about that. But there is a.. read

There’s a lot going on in the financial technology (or fintech) world—things that will impact not.. read
I’ve been doing a lot of speaking—virtually of course—to industry groups made up of small- and.. read
There has been a major boost in business technology trends in the year of 2020. This.. read

Maybe you saw the discussion I had with John Horner, Ivan Mehta and Tom Berdan. If.. read

If there’s anything the recent economic downturn has taught us it’s that maintaining a healthy cash.. read

With tax day just a few days away, here are some tips that we hope will.. read
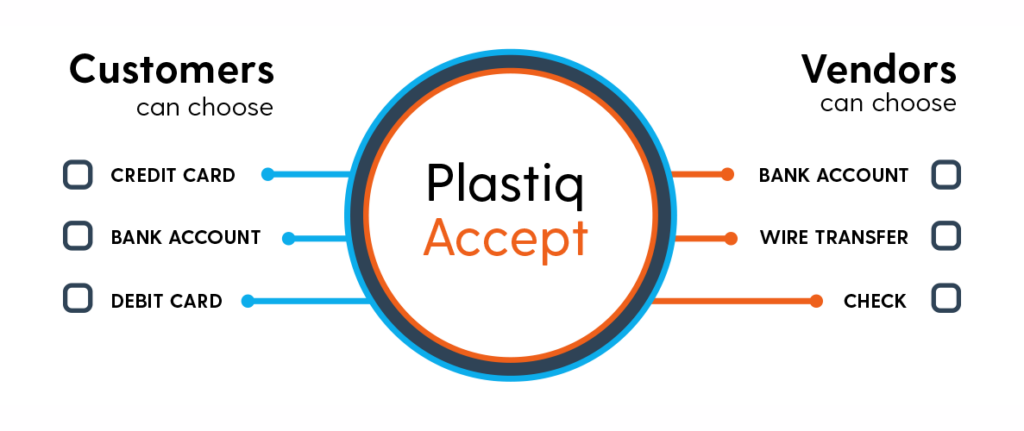
If your business only accepts cash, checks, or electronic bank transfers, and you feel like credit.. read
Investment Will Be Used to Equip SMBs with Expanded Payment Options that Enable Them to Maximize.. read

When you get an emergency call from a customer who needs something right away do you.. read

American entrepreneur Oded Wurman has a burgeoning small business. He provides software to emergency responders who.. read

It amazes me how, in 2020, so many small business owners don’t take advantage of credit.. read
Many businesses are struggling to navigate their way through the current Coronavirus pandemic. Some have been.. read

With shelter-in-place orders being enacted across the globe, small business owners everywhere are in crisis mode,.. read

San Francisco, CA – April 24, 2020 – We’re proud to share that Plastiq has been.. read

Dear Customers, Friends, and Community, No doubt you have received many updates and messages from companies,.. read

Published on March 13, 2020 At the time of publishing this post, the World Health Organization.. read
Published on March 4, 2020 Like so many around the world, as we monitor the coronavirus.. read

Many people wait to file their taxes close to the deadline, but there are good reasons.. read

Common Cash-Only Write-Offs Which Can Be Paid With Plastiq This information is for educational purposes only… read

Regardless of the season, there’s always somewhere in the world worth exploring. However, the desire to.. read
We’re excited to be named today to Forbes’ 2020 Fintech 50 list. The publication highlights the.. read

Prestigious Industry Award Recognizes Fintech Companies with Significant Company Growth SAN FRANCISCO – February 12, 2020.. read

Editor’s Note: This is a guest post by PingPong Payments You’ve found profitable products, mastered the.. read

One of the major reasons that small businesses fail is from a lack of working capital… read

Obtaining great seller feedback on Amazon can play a vital role in how well your product.. read

One of the most sought after prizes in the e-commerce industry is to land a product.. read
E-Commerce sellers have a lot to pay attention to, particularly when it comes to financial metrics.. read

Fully understanding your cash flow can help your business grow exponentially. The first step is to.. read

Sophisticated, seamless integration saves time and money, ensuring businesses have an up-to-date, accurate record of all.. read

3 emerging trends in customer behavior and how your business can adapt. Business trends come and.. read

If you’re an e-commerce seller, you cannot miss two big conferences coming up next week in.. read

Following the Supreme Court ruling on South Dakota v. Wayfair, enforcement of sales tax laws on.. read

Selling products on Amazon is a great way to make a seven-figure income (or more).  But.. read

By Keaton Goldsmith Convenience, but With Strings Attached Selling on Amazon opens up a huge market.. read

The Competition is Stiff E-commerce is booming, but with heavy-hitters like Amazon, Alibaba, and others dominating.. read

U.S. Bank is the Latest Financial Institution to Enable its SMB Visa Cardholders to Pay Vendors.. read

Plastiq’s benefits for Visa cardholders just keep getting better! Today, we are highlighting our commitment to.. read

You may already be familiar with Plastiq’s international payment service, which enables your business to make.. read
Plastiq is just like a money transfer service for small businesses, but offers so much more… read

It’s that time of year when tuition payments are due! But maybe the pain of a.. read

We’re extremely pleased to announce the expansion of Plastiq’s Accelerated Check Payments offering. Expedited check payments.. read
As a restaurateur in a highly competitive market, serving the customer means having enough food throughout.. read

Tired of high interest loans and lines of credit? As a general contractor, you know all.. read

Ever wondered how you can increase your cash flow? Using Plastiq’s new benefit calculator we can.. read

Plastiq is a modern payments company designed to unlock access to your existing credit, so you.. read
What to expect In the pair programming session, YOU will be the star and you will.. read
(Updated September 3, 2019: EU countries can now be paid as well.) (Updated August 6, 2019: Japan,.. read

By Janet Berry-Johnson, CPA This information is for educational purposes only. Please consult with your tax.. read
You’ve likely read our many blog posts around our interview process including what we look for.. read

One of the most popular questions we receive is, “Which credit card can I use for.. read

Currently, our company is experiencing a rapid growth phase. We plan to triple the size of.. read
This is a question I field quite frequently since we ramped up our Engineering hiring efforts.. read
I must start by saying that my onboarding with Plastiq has been the best of my.. read

If there is one thing I love doing, it’s talking about Plastiq. Last year we received.. read
Tell us a little about yourself. I joined Plastiq in early 2016. From then through to.. read
Credit card usage is at an all-time high, with Americans carrying nearly $4 trillion of credit.. read

At Plastiq today, we are hiring for a lot of Engineering roles. At various prior companies.. read

On the heels of two very exciting announcements for Plastiq, our Series C funding rounds in.. read

Tell us a little about yourself. I started working at Plastiq in November of last year.. read
I am absolutely delighted to share that Plastiq has been named one of the “Best Places.. read

Plastiq is delighted to announce that we will be exhibiting at Built in Boston’s upcoming¬†Top Companies.. read
Artificial intelligence, machine learning, deep learning, skynet. It seems you can’t find a budding new startup.. read
The Massachusetts Conference for Women was held in Boston on Dec 11th and 12th. It’s the.. read
To help people better understand more about how Plastiq works and can be best utilized by.. read

Plastiq’s story is a tale of two cities – namely Boston and San Francisco. Boston –.. read

My co-founder Dan and I are thrilled to announce that after four years in the Bay.. read
Earlier this year, I first came across the site KeyValues.com. I was really impressed with the.. read

As a software engineer at Plastiq, it is likely that you’ll attend (or even lead) a.. read

I was speaking recently with a friend who is a Head of People at another company… read

Admit it, engineers. You don’t want to work on CSS if you can possibly avoid it… read